Over the last decade, an increasing amount of effort has been spent on constructing and, then, simulating powerful brain models that can greatly help in unraveling the mysteries of the human brain (see for instance the EU flagship Human Brain Project). Whereas these models are powerful and constantly come closer to the real-brain functionality, however they are typically very computationally intensive, to the point that common platforms such as multicore CPUs fall short of reaching reasonable execution times.
We have thus turned to more powerful platforms, such as the FPGA-based, Maxeler Dataflow Engines (DFEs). While FPGAs receive high marks when it comes to performance acceleration, nevertheless, their limited capacity is not sufficient for implementing large-scale brain simulations comprising (thousands or) millions of neurons.
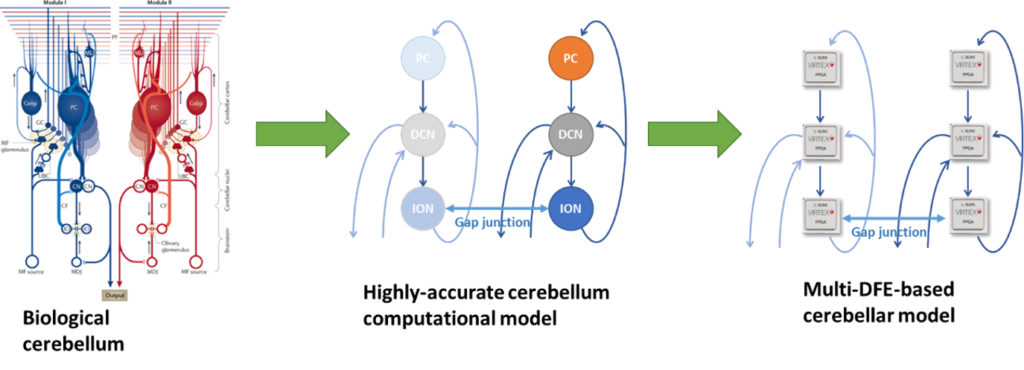
The subject of this MSc-thesis topic is to extend a currently implemented, biologically accurate, simulation kernel (comprising a single DFE) to span multiple DFEs. This is novel thesis work from the NeuroComputing Lab on low-latency accelerator interconnects. Such low-latency interconnect permitting disaggregated and host-free synergy across accelerator platforms is a key-enabling technology for the now trending Cloud-HPC platforms (e.g. Amazon AWS). If the inter-DFE communication challenges are recognized and sufficiently dealt with, this extension is expected to double the achievable real-time brain simulation capabilities with every new DFE added. This work represents a culmination of 9 years of work within the department and will permit top, world-first brain simulations with high-impact publication value.
The student is expected to analyze the original single-DFE neural models, identify latency-sensitive sections and potential optimizations and, then, deploy (through the DFE tool flow) the original application onto a multi-DFE setup. A strong background in FPGA coding is encouraged, but primarily students of high quality and strong commitment are sought.
Keywords: Multi-FPGA design; off-chip communication, hardware architecture, dataflow
Prerequisites: VHDL or Verilog; MaxJ preferred; basic knowledge of hardware tools and Vivado C preferred.
Optionally: Docker containers, jupyter notebooks.
Contact: Christos Strydis